
Last Updated on June 30, 2024 by E. Scott
Full stack web development entails many dozens of moving parts. Moving parts in both the front and backend. Full stack web development will vary from one company to the next. It’s not industry centric. Nor is there an exact roadmap to follow. Moreover, the technologies used to accomplish thereof will change as well.
Full stack web development cannot be taught in entirety in a bootcamp or an online class(s). To fully grasp the idea and grow our skills in this rapidly changing arena, we need experience. Experience building complex UIs with powerful frameworks such as React and Angular. It can also be beneficial to know what’s happening under the hood of these frameworks shall there be a problem. Which is why it’s wise to know TypeScript and JavaScript. To have built a variety of small and large apps;
Same goes for the backend. Some companies use Spring while others use C#. My last company used Node and Spring Boot. Before that I worked briefly with Django. I recently took on a large endeavor with Node and Mongo. Sure, many of the concepts are similar. But syntax, error handling, deployment, and many other tasks are quite different.
Table of Contents
Layouts
Layouts are a crucial part of full stack web development. They serve as the basis of the entire project. Regardless of how complex or basic the frontend is, every app needs layouts. These may begin as a sketch done on paper or with the program, Sketch. Adobe and many other companies have programs for designers to quickly add drop downs, forms, etc.
Thereafter these low fidelity concepts go to legal teams and stakeholders for review. Sometimes low fidelity mocks are bypassed moving directly to high fidelity. Some have fonts and pixel dimensions while others don’t. Adobe XD is a good tool, but can be frustrating to meet the designers exact pixel dimensions.
Layouts not only serve as a visual guide. They also provide developers a way to see exactly what the features are and talk about how they’ll be built. How will data flow from one page to the next? What backend calls need to be made? This is the time for dev discussions to flourish.
Frontend Development
Frontend development is usually stage two in my experience. Once layouts are approved and revised, components are created. Some of which may come from a library while others are developed from scratch. Services are written which may house reusable functions or serve as middleware. Middleware that sends and receives data or makes http requests.
TypeScript for instance frequently uses RxJS to refine payloads. Observables are meant to share/ broadcast values. Services are generally where devs will make API calls, save, and revise data. Every framework has a feature that isolates functions for global use. Be it services or the Context API. Generic files can be created in vanilla JavaScript apps that, conceptually do the same thing.
Frequent frontend challenges during full stack web development include but are not limited to error handling, getting values to populate at the right time, or general speed and performance. Frontends can get very complex. Or they can have a minute UI with a complex backend. To quickly enhance your JavaScript knowledge, check out this onslaught of projects. You may also find this post on routing helpful.
CSS
I don’t believe I’ve ever met a developer that enjoys CSS as much as I do. Maybe it’s because I began my career building rich media units. Rich media were often times rather fun and creative endeavors that entail animation, graphics, unique tracking systems, and easy API payloads. Moreover, so much of my dev experience has entailed crazy complex UIs, so I got darn good at CSS and SCSS.
But I digress. CSS can get quite unwieldy. I’ve seen dedicated full stack devs who insist on writing inline styles or simply don’t know how to write CSS at all. I usually alphabetize my styles and very cognizant as to which should be in their own namespace and what styles should be global.
Naming conventions are also very important. So is careful attention to swapping out classes or over riding rules. In addition to deleting unused classes. Keeping CSS and SCSS files very tidy is big time important. We can optimize styles via libraries, importing styles, and using variables. Just to name a few.
Responsive Content
Responsive content undoubtedly resides on the frontend. This is the process of conforming everything to the screen size. Regardless of where I work, I usually see Bootstrap used. And it drives me nuts because so many devs think it’s ok to use an entire library just to make columns. Bootstrap gets in the way of everything in my opinion. I avoid it all costs.
Instead, I do everything manually to obtain full control of the UI at any size. This is done by either adding breakpoints or using a service and an observable. Something simple that automatically calculates the width.
@media screen and (max-width: 1300px) { }
@media (min-width: 1200px) and (max-height: 700px) { }
@media screen and (max-width: 992px) { }// Set a resize event on a parent
host: {
'(window:resize)': 'onWindowResize($event)'
}
// Set the values
someWidth: number = window.innerWidth;
private winWidthSource = new BehaviorSubject(this.someWidth);
currentWidth$ = this.winWidthSource.asObservable();
// Update the width
changeWidth(newValue: number) {
this.winWidthSource.next(newValue);
return newValue;
}
// subscribe/ broadcast the new values
this._service.categoryNavigationMenu$.pipe(takeUntil(this.unsubscribe$))
.subscribe((val) => {
val ? (this.fullExplanation = false) : '';
});
// Use the value
*ngIf="screenSize > 605"Responsive content can be extraordinarily difficult at times. In my experience, UI’s can be drastically overhauled in each layout. In turn, the frontend needs to be malleable and maintained with precision. Otherwise, things get very messy, quickly. UI command at this level is usually done by a Sr. UI Engineer or Frontend Developer.
Error Handling
Error handling is very important in full stack web development. Everything in this category boils down to UX and information architecture. A users experience determines if they purchase a product. Whether or not they sign up. Whether they leave the site altogether and do thereof to the nearest competitor. Information architecture is similar.
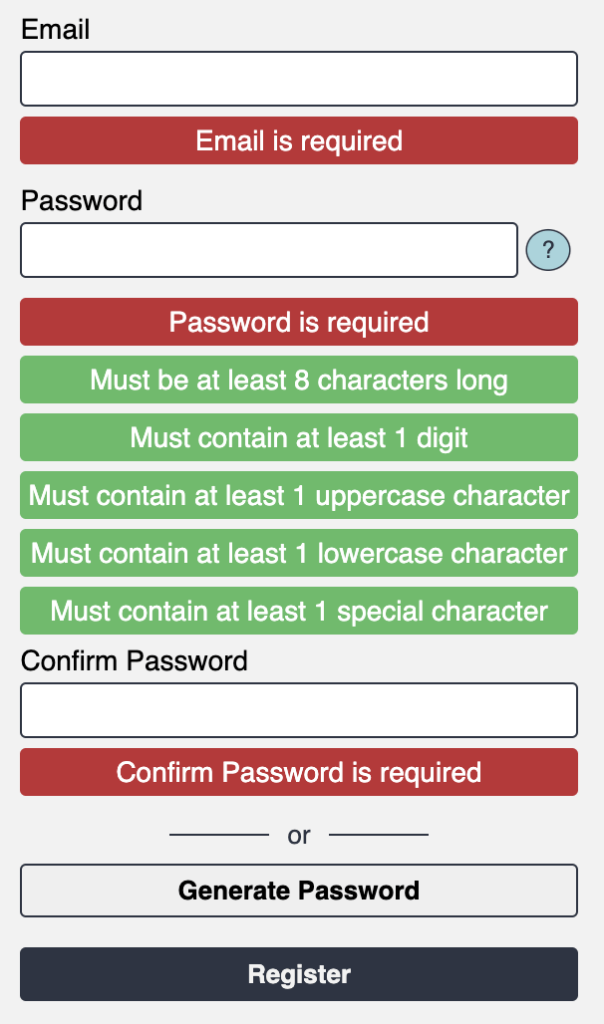
If errors occur in said processes, users need to know about it. Form field errors should execute before form submission in my opinion. Some sites don’t even have inbuilt form error handling, making the process beyond frustrating. Especially if it’s a government website or something mandatory like car registration.
Errors can be displayed as notifications, top and centered, or any other way that jives with the UI. They may come from the frontend such as in the case of a form. Or a 500 error from a failed API. 500 errors can be used for anything users don’t need to know about. Just something indicative of a problem beyond their ability to fix. Some errors will have a code such as 401 while others are strictly UI related.
Backend Development
Backend development undoubtedly plays a crucial role in every full stack web development project. At my previous company, the backend was Spring Boot, Node, and Mongo. Mongo because we stored such an array of data. Most of which was incongruent to one another. Hence the non relational DB. Another company I worked at used C#/.NET and Spring Boot with SQL and NoSQL.
If a company is using micro services or micro frontends, there can be a different backend for every service. I recently used Single Spa. This framework supports micro frontends. Meaning, in large proprietary applications, such as finance, there could be 20 micro frontends. These are all independently running full stack applications. One may use Angular/ C# while another uses Svelte/ Spring Boot.
The backend is a mixture of databases and servers controlling user access and content. It’s comprised of collections of data. Login credentials are validated on the frontend, but also on the backend. Each of which checks for different things. Sometimes there’s overlap though. Databases can be Oracle, MongoDB, MySQL, or PostgreSQL.
Developers use specialized queries to pull, filter, refine, and sort data. Backend architects have the propensity to create a birds eye view of the data flow. In turn, they’ll design entire systems often times overseeing large projects. Essentially taking on the same role as a Senior Frontend Developer would with frontend heavy applications.
There’s been instances where I’ve been tasked with creating the entire frontend, including the data. This is, creating the objects via mock JSON data. Creating the entire process purely with dummy data. Then working closely with the backend devs to create the necessary APIs. Every environment is unique. Some have more problems and obstacles than others. Regardless, it’s always a tedious process.
SQL vs. NoSQL
These two acronyms are related to how databases are structured. A structured query is indicative of data stored like an Excel file. In tables and rows. The antithesis is non structured data (NoSQL). SQL stores tables of data and links other tables to thereof.
We use SQL in the event of handling repetitive data. If for instance, we’re making an application for a school where every record has a name, address, and phone, SQL may be the way to go. It’d be easy to repeat rows and create another table with each students classes.
Otherwise, if the data varies, NoSQL may be the wiser option. Each method requires a model. A model is a blueprint of the data. If multiple models are needed, NoSQL is the answer. It’d be far more tedious to create a system of rows and columns with data that differs. NoSQL is based on documents vs tables. Documents can differ in value and length.
In regards to full stack web development, it’s our job to decide ahead of time which is the best option. In the case of SQL, querying may take longer due to potentially searching multiple tables. NoSQL may be faster, but there could be repeated data in each document. Both systems have their pros and cons. The answer lies in our chosen data structure.
OAuth
OAuth will most likely be a part of any full stack web development project. Upon it’s inception, the goal was to create a system where users were not forced to enter their login credentials to third party apps.
Before OAuth, apps would ask for third party login credentials in order to connect users’ contacts. And because many users will do anything to do thereof, they’d be happy to fork over their username and password. This may be “safe” in some cases, but…it’s a terrible method.
I once read an analogy but don’t know who to credit (apologies). When we check into a hotel we provide the front desk with an ID, credit card, etc. We’re then given an access card that opens the room. It also opens the pool, the gym, and numerous other areas on the property. But the only one who knows our true identity is the front desk. This is the concept behind OAuth.
The benefit of this process is companies don’t need to trust developers with login credentials. Users are sent to a proprietary OAuth server to login. This process limits security vulnerabilities. In turn the attack surface is greatly reduced.
If users need to enter their password in multiple locations, attackers have more opportunities to steal passwords. Moreover, this leads to one location to build on OAuth. Such as multi factor authentication. OAuth enables features like this to be built and maintained in one location.
JSON Web Token
JSON Web Tokens (JWT), in my experience are used to assist in authorization. Undoubtedly, a key step in full stack web development. In regards to login, there’s both authentication and authorization. Authentication is comparing a users’ login credentials to a database record.
Authorization is determining what said users have access to. Authentication may or may not occur on the same server as authorization. Regardless, they need to communicate. Communication occurs via a JWT.
A JWT is an encrypted, alphanumeric string of characters. Characters that contain information of decrypted data. So when a user logs in, their credentials are sent to be authenticated. A JWT is then constructed containing information about their session such as expiration and permissions. Read more about it here.
API Development
Full stack web development revolves almost entirely around API development. Application programming interfaces are a set of guidelines about how to interact with code. APIs enable developers to send and receive information. Modify it, delete it, and update thereof.
A recent API I worked on was a C# backend that retrieved login credentials. The API sent the credentials to an OAuth server which responded with a token. The API then sent the token to the client. If a user entered a set of wrong credentials said number of times, the API responded with an order to redirect. I built the same concept in a MEAN stack app.
API’s are also used to supply the UI with data. Several contracts ago I worked at a data company. Every UI was data driven. Each of which contained data visualizations and tables. All of which were derived from several APIs. Every time pagination was changed, the API was pinged. When a table search query was performed, the API was sent the query which was sent to Mongo.
APIs are literally everywhere in full stack web development. All of us use them everyday regardless of what we do on the internet. Online shopping, video chat, loading page content, searching a blog for posts; none of these tasks could be performed without APIs.
CORS
Cross Origin Resource Sharing is a common issue. Devs will get this error when two resources try to communicate from different domains. In local for instance, an API on port 3000 won’t be able to successfully communicate w/ the UI on port 4000.
Ports are viewed as different domains. This protocol is a safety measure because websites shouldn’t natively be accessing data on extraneous servers. Intentionally exposing a server API needs header configuration. This can be a pain point when working with numerous teams.
Storage in Full Stack Web Development
When building or testing full stack web development you’re bound to work with caching. Caching is the HTML, CSS, and JavaScript that’s temporarily saved in the browser. Browsers will automatically save the core frontend files to expedite loading time. This can sometimes be frustrating while working with payloads, style, or structural changes. Changes won’t always reflect due to caching.
Also meant to expedite loading time is local storage. This browser API stores key value pairs. I recently used local storage to avoid pinging an API on each payload. I stored JSON on each page load, then checked if it existed thereafter. In turn, pages were loaded from local storage vs the server.
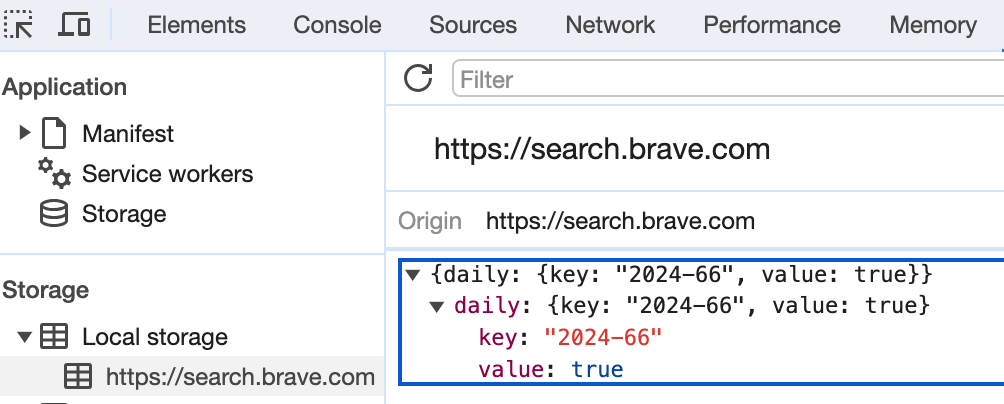
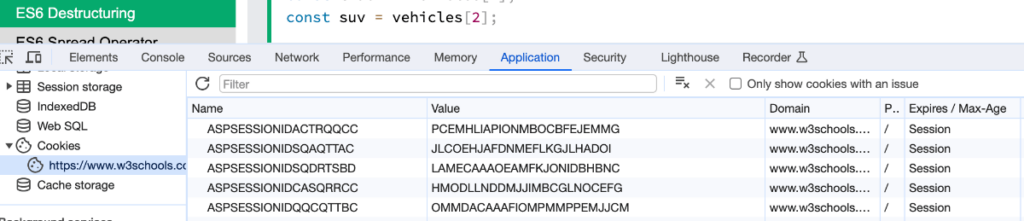
Cookies are also stored in the browser. Local storage can hold up to 10mb in most browsers, but cookies can only amount to 4kb. Both local storage and cookies however can be viewed via DevTools. Cookies are primarily used in full stack applications such as WordPress and Rails apps. Or sites with SSR pages.
This is due to the fact cookies need to be on the same domain, or will be viewed as third party cookies by browsers. And some browsers enable users to block third party cookies as they’re often used for tracking and advertising. When they are used, they contain a session ID that references a users credentials and login status. It’s because of this concept JWT’s are used with SPAs because they’re backend agnostic. JWT’s will work regardless of the backend URL. Upon heavy usage of React and Angular, decoupled backends are very common. Hence, JWT popularity.
Documentation
Ugh, documentation. Is it safe to say, it’s rare to walk into a new place and there’s ample documentation available? Has anyone experienced this? What’s your opinion on documentation for proprietary software? What about APIs? Have you found that most or many APIs are well documented?
For two years now, I’ve been working at a financial institution. And the documentation is far from perfect. The documentation in a library I work with has a terminal command for major and minor which definitely helps. I believe it looks at the branch changes and decides what it should be bumped up to (1.2.1 or 1.2.4). Run the major terminal command and it bumps it to 2.0.0.
Large companies often use Confluence. This is massive system that enables anyone with access to create new pages. It’s like an internal blogging solution. Teams create docs on their endeavors. Stakeholders create docs on protocol. And admin create docs on URLS, logins, permissions, etc.
I’m currently working on documentation for a massive single page app I’ve created. I’m sure there’s a dedicated industry format, but I simply think it’s wise to include explanations on features, payloads, APIs, and perhaps components.
Leave a Reply